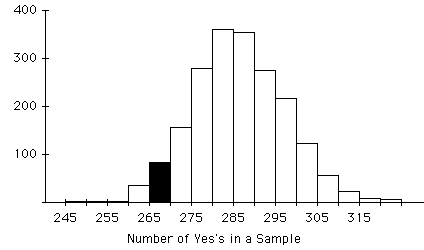
A histogram showing 2000 random samples, each having500 students, recording the number of students in each sample who answered "yes" to the question of whether they believed they could be president.
Ask especially about making a caption for the histogram. Say that we realize that this is difficult, because a good caption should capture all that is going on, and there is a lot going on. Also, remind them that long captions are okay when short ones don't work.
Example:
A histogram showing 2000 random samples, each having500 students, recording the number of students in each sample who answered "yes" to the question of whether they believed they could be president.
BUT ...
Note to other researchers: The issue being raised here is really one of measurement, not just statistical measurement, but measurement in general -- how to assign measures to attributes of objects so that they lead to the comparative judgements we intend. The typical approach to raising issues of measurement is to have students order objects according to the attribute they wish to quantify. But that approach often avoids the central issue of measurement -- when do two apparently diferent objects have the same measure. This issue entails similarity, and hence ratio. Hence, when ratio is the appropriate measure, asking students to order objects often allows them to do the task without needing to conceive of the measure as a ratio.
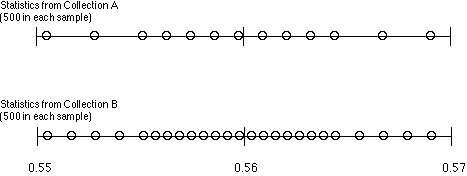
Observations that came up during class
- The two collections have different numbers of samples. ("Yes, I did that on purpose. It makes it harder to form judgements by eyeballing them.")
- The two collections have the same range, so if we went strictly by range they would be equally variable.
- But the top collection looks more spread out. If we go by how far apart the individual samples are, the Collection A is more variable.
- But the bottom one has more samples, and more of them are farther away from 0.56. So, if we went by how many samples are farther from the center, Collection B would be more variable.
- Beta said "But if you look at how evenly they are spaced, they are both spaced about as even."
I took Beta's observation as an opportunity to describe one conventional way to look at variability. It is to look at what fraction of the samples appear within various ranges.
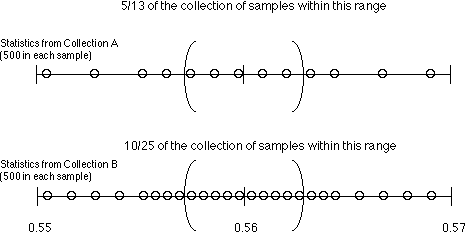
If we look at what fraction of the statistics caclulated from each group lie within, say ±0.003 of 0.56, we see that in Collection A we capture 5/13 of the samples and in Collection B we capture 10/26 of the samples. So the two are very close in variability by this measure.